스트림(Stream)은 자바 8부터 추가된 컬렉션(배열 포함)의 저장 요소를 하나씩 참조해서 람다식(함수적-스타일)으로 처리할 수 있도록 해주는 반복자이다.
반복자 스트릠
자바 7 이전까지는 List 컬렉션에서 요소를 순차적으로 처리하기 위해 Iterator 반복자를 사용했다.
public class Test {
public static void main(String[] args) {
List<String> list = Arrays.asList("홍길동", "김아무개", "김도시");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()) {
String name = iterator.next();
System.out.println(name);
}
System.out.println("=====");
list.stream().forEach(System.out::println); // stream을 이용하면 간단히 바꿀 수 있다.
}
}스트림의 특징
Stream은 Iterator와 비슷한 역할을 하는 반복자이지만, 람다식으로 요소 처리 코드를 제공하는 점과 내부 반복자를 사용하므로 병렬 처리가 쉽다는 점, 중간 처리와 최종 처리 작업을 수행하는 점에서 많은 차이가 있다.
- 람다식으로 요소 처리 코드를 제공한다.
- Stream이 제공하는 대부분의 요소 처리 메서드는 함수적 인터페이스 매개 타입을 가지기 때문에 람다식 또는 메서드 참조를 이용해서 요소 처리 내용을 매개 값으로 전달할 수 있다.
- 내부 반복자를 사용하므로 병렬 처리가 쉽다.
- 외부 반복자란 개발자가 코드로 직접 컬렉션의 요소를 반복해서 가져오는 코드 패턴을 말하는데 index를 이용하는 for문과 Iteratir를 이용하는 while문은 모두 외부 반복자를 이용한다.
- 내부 반복자는 컬렉션 내부에서 요소들을 반복시키고, 개발자는 요소당 처리해야 할 코드만 제공하는 패턴을 말한다.
- 병렬 처리가 컬렉션 내부에서 처리된다.
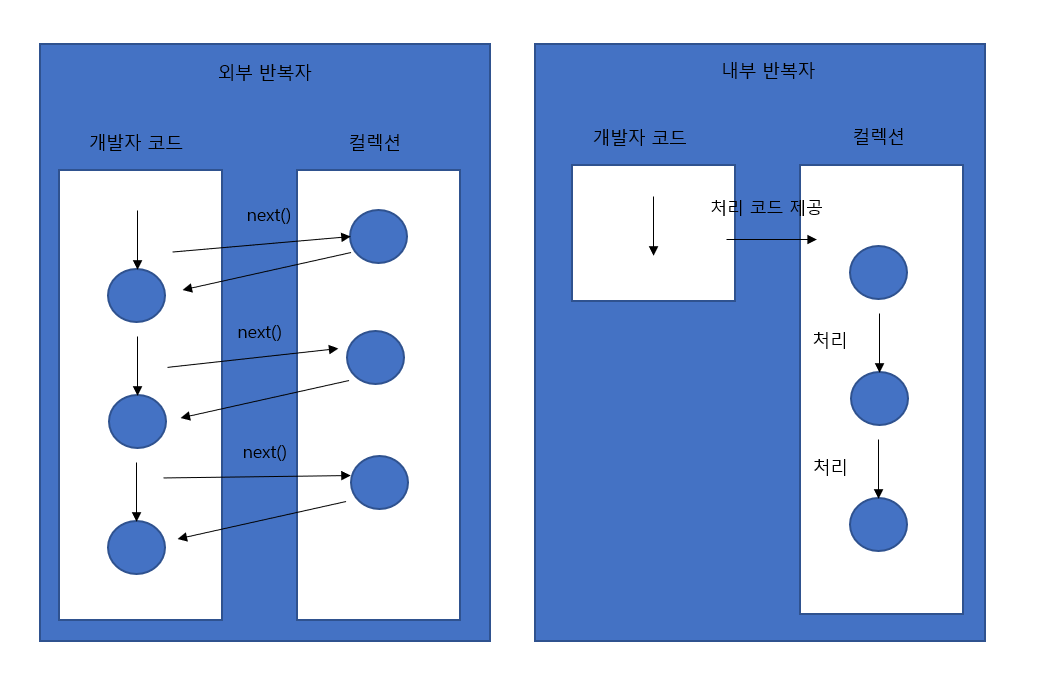
- 스트림은 중간 처리와 최종 처리를 할 수 있다.
- 중간 처리에서는 매핑, 필터링, 정렬을 수행하고 최종 처리에서는 반복, 카운팅, 평균, 총합 등의 집계 처리를 수행한다.
스트림의 종류
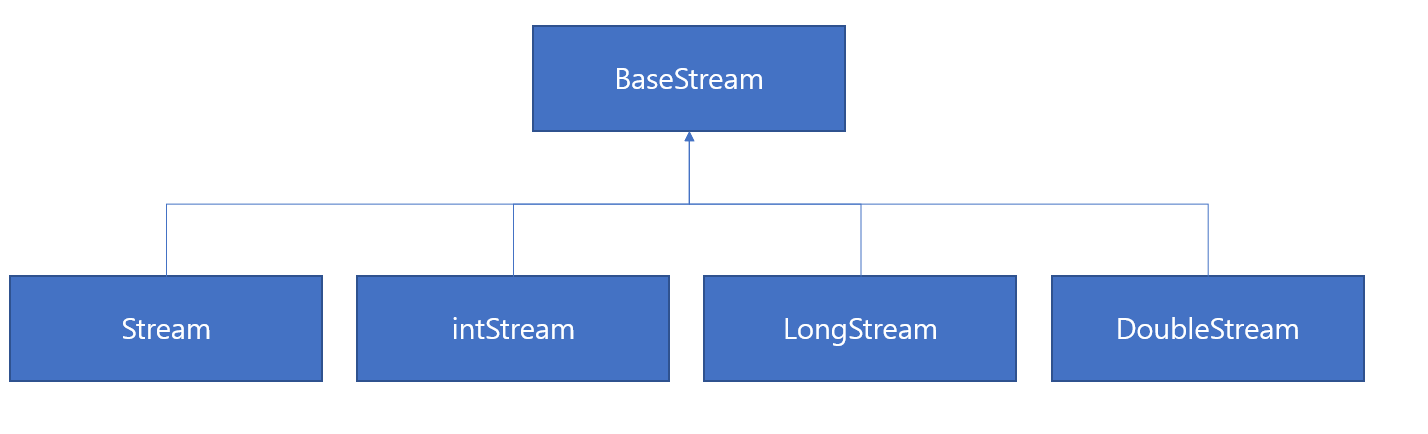
- 컬렉션으로부터 스트림 얻기 : studentList.stream();
- 배열로부터 스트림 얻기 : Arrays.stream(strArray);
- 숫자 범위로부터 스트림 얻기 : IntStream.rangeClosed(1, 100);
- 파일로부터 스트림 얻기 : Path path = Paths.get("path"); Files.lines(path, Chareset.defaultCharset());
- 디렉토리로부터 스트림 얻기 : Files.list(path);
스트림 파이프라인
대량의 데이터를 가공해서 축소하는 것을 일반적으로 리덕션이라고 하는데, 데이터의 합계, 평균값, 카운팅, 최대값, 최소값 등이 대표적인 리덕션의 결과물이라고 볼 수 있다.
컬렉션의 요소를 리덕션의 결과물로 바로 집계할 수 없을 경우에는 집계하기 좋도록 필터링, 매핑, 정렬. 그룹핑 등의 중간 처리가 필요하다.
중간 처리와 최종 처리
- 중간 처리 : 필터링, 매핑, 정렬, 그룹핑 등
- 최종 처리 : 합계, 평균, 카운팅, 최대값, 최소값
파이프라인에서 최종 처리를 제외하고는 모두 중간 처리 스트림이다.
중간 스트림이 생성될 때 요소들이 바로 중간 처리 되는 것이 아니라 최종 처리가 시작되기 전까지 중간 처리는 지연 된다.
최종 처리가 시작되면 비로소 컬렉션의 요소가 하나씩 중간 스트림에서 처리되고 최종 처리까지 오게 된다.
public class StreamPipelineTest {
public static void main(String[] args) {
List<MyMember> list = Arrays.asList(
new MyMember("김", MyMember.MALE, 30),
new MyMember("이", MyMember.FEMALE, 31),
new MyMember("박", MyMember.MALE, 32),
new MyMember("홍", MyMember.FEMALE, 33),
new MyMember("김", MyMember.MALE, 34)
);
double ageAvg =
list.stream().filter(m -> m.ss == MyMember.MALE).mapToInt(MyMember::getAge).average().getAsDouble();
System.out.println("평균 나이 : " + ageAvg);
}
private static class MyMember {
public static int MALE = 0;
public static int FEMALE = 0;
private String name;
private int ss;
private int age;
public MyMember(String name, int ss, int age) {
this.name = name;
this.ss = ss;
this.age = age;
}
public int getSs() {
return ss;
}
public int getAge() {
return age;
}
}
}중간 처리 메소드와 최종 처리 메서드
| 종류 | 리턴 타입 | 메서드(매개변수) | 소속된 인터페이스 | |
| 중간 처리 | 필터링 | Stream IntStream LongStream DoubleStream |
distinct() | 공통 |
| filter(...) | 공통 | |||
| 매핑 | flatMap(...) | 공통 | ||
| flatMapToDouble(...) | Stream | |||
| flatMapToInt(...) | Stream | |||
| flatMapToLong(...) | Stream | |||
| map(...) | 공통 | |||
| mapToDouble(...) | Stream, IntStream, LongStream | |||
| mapToInt(...) | Stream, LongStream, DoubleStream | |||
| mapToLong(...) | IntStream, LongStream, DoubleStream | |||
| asDoubleStream() | IntStream, DoubleStream | |||
| asLongStream() | IntStream | |||
| boxed() | IntStream, LongStream, DoubleStream | |||
| 정렬 | sorted | 공통 | ||
| 루핑 | peek | 공통 | ||
| 최종 처리 | 매칭 | boolean | allMatch(...) | 공통 |
| boolean | anyMatch(...) | 공통 | ||
| boolean | noneMatch(...) | 공통 | ||
| 집계 | long | count() | 공통 | |
| OptionalXXX | findFirst() | 공통 | ||
| OptionalXXX | max(...) | 공통 | ||
| OptionalXXX | min(...) | 공통 | ||
| OptionalDouble | average() | IntStream, LongStream, DoubleStream | ||
| OptionalXXX | reduce(...) | 공통 | ||
| int, long, double | sum() | IntStream, LongStream, DoubleStream | ||
| 루핑 | void | forEach(...) | 공통 | |
| 수집 | R | collect(...) | 공통 | |
- 필터링
- distinct()
- filter()
- 매핑
- flatMapXXX()
- map()
- asXXXStream()
- boxed()
- 정렬
- sorted()
- 루핑
- peek()
- forEach()
- 매핑
- allMatch()
- anyMatch()
- noneMatch()
- 기본 집계
- sum()
- count()
- averate()
- max()
- min()
- Optional 클래스 : 단순히 집계 값만 저장하는 것이 아니라, 집계 값이 존재하지 않을 경우 디폴트 값을 설정할 수도 있고, 집계 값을 처리하는 Consumer도 등록할 수있다.
- isPresent()
- orElse()
- ifPresent()
- 커스텀 집계
- reduce()
- 수집 : 필요한 요소만 컬렉션으로 담을 수 있고, 요쇼들을 그룹핑한 후 집계할 수 있다.
- collect()
- toList()
- toCollection()
- toMap()
- toConcurrentMap()
- collect()
- 요소를 그룹핑해서 수집
- groupingBy()
- 그룹핑 후 매핑 및 집계
- mapping()
- averaginDouble()
- counting()
- joining()
- maxBy()
- minBy()
- summingInt()
- summingLong()
- summingDouble()
collect 예제
public class MaleStuent {
private List<MyMember> list;
public MaleStuent() {
this.list = new ArrayList<>();
System.out.println(" MaleStuent " + Thread.currentThread().getName());
}
public void accumulate(MyMember m ) {
list.add(m);
System.out.println("accumulate " + Thread.currentThread().getName());
}
public void combine(MaleStuent m) {
list.addAll(m.getList());
System.out.println("combine : " + Thread.currentThread().getName());
}
private Collection<? extends MyMember> getList() {
return this.list;
}
public static void main(String[] args) {
List<MyMember> list = Arrays.asList(
new MyMember("김", MyMember.MALE, 30),
new MyMember("이", MyMember.FEMALE, 31),
new MyMember("박", MyMember.MALE, 32),
new MyMember("홍", MyMember.FEMALE, 33),
new MyMember("김", MyMember.MALE, 34)
);
Stream<MyMember> listStream = list.stream();
Stream<MyMember> maleStream = listStream.filter(m -> m.getSs() == MyMember.MALE);
Supplier<MaleStuent> s = () -> new MaleStuent();
BiConsumer<MaleStuent, MyMember> acc = (ms, ss) -> ms.accumulate(ss);
BiConsumer<MaleStuent, MaleStuent> combiner = (ms1, ms2) -> ms1.combine(ms2);
MaleStuent maleStuent = maleStream.collect(s, acc, combiner);
MaleStuent maleStuent1 = list.stream().filter(t -> t.getSs() == MyMember.MALE).collect(
() -> new MaleStuent(),
(r, t) -> r.accumulate(t),
(r1, r2) -> r1.combine(r2)
);
MaleStuent maleStuent2 = list.stream().filter(m -> m.getSs() == MyMember.MALE).collect(MaleStuent::new,
MaleStuent::accumulate, MaleStuent::combine);
}
}
GroupingBy 예제
public class GroupingByTest {
public static void main(String\[\] args) {
List list = Arrays.asList(
new MyStudent("김", 30, MyStudent.Ss.MALE, MyStudent.City.Seoul),
new MyStudent("이", 31, MyStudent.Ss.FEMALE, MyStudent.City.Pusan),
new MyStudent("박", 32, MyStudent.Ss.MALE, MyStudent.City.Pusan),
new MyStudent("홍", 33, MyStudent.Ss.FEMALE, MyStudent.City.Pusan),
new MyStudent("김", 34, MyStudent.Ss.MALE, MyStudent.City.Seoul)
);
Map<MyStudent.Ss, List<MyStudent>> mapBySs = list.stream().collect(Collectors.groupingBy(MyStudent::getSs));
System.out.println("남학생");
mapBySs.get(MyStudent.Ss.MALE).stream().map(x -> x.getName()).forEach(System.out::println);
System.out.println("여학생");
mapBySs.get(MyStudent.Ss.FEMALE).stream().map(x -> x.getName()).forEach(System.out::println);
System.out.println();
Map<MyStudent.City, List<MyStudent>> mapByCity = list.stream().collect(Collectors.groupingBy(MyStudent::getCity));
System.out.println("서울");
mapByCity.get(MyStudent.City.Seoul).stream().map(x -> x.getName()).forEach(System.out::println);
System.out.println("부산");
mapByCity.get(MyStudent.City.Pusan).stream().map(x -> x.getName()).forEach(System.out::println);
}
}병렬 처리
멀티 코어 환경에서 하나의 작업을 분할해서 각각의 코어가 병렬적으로 처리하는 것을 말하며, 병렬 처리의 목적은 작업 처리 시간을 줄이기 위함이다.
동시성(Concurrentcy)와 병렬성(Parallelism)
동시성은 멀티 작업을 위해 멀티 스레드가 번갈아가며 실행하는 성질을 말하고, 병렬성은 멀티 작업을 위해 멀티 코어를 이요해서 동시에 실행하는 성질을 말한다.
데이터 병렬성
전체 데이터를 쪼개어 서브 데이터들로 만들고 이 서브 데이터들을 병렬 처리해서 작업을 빨리 끝내는 것을 말한다.
자바 8에서 지원하는 병렬 스트림은 데이터 병렬성을 구현한 것이다.
작업 병렬성
서로 다른 작업을 병렬 처리하는 것을 말하며 작업 병렬성의 대표적인 예는 웹 서버이다.
포크조인 프레임워크
병렬 스트림은 요소들을 병렬 처리하기 위해 포크조인 프레임워크를 사용한다.
런타임 시에 포크조인 프레임워크가 동작하는데, 포크 단계에서는 전체 데이터를 서브 데이터로 분리한다. 그리고 나서 서브 데이터를 멀티 코어에서 병렬로 처리한다.
조인 단계에서는 서브 결과를 결합해서 최종 결과를 만들어 낸다.
병렬 스트림 생성
paralleStream() 메서드는 컬렉션으로부터 병렬 스트림을 바로 리턴하고 어떤 방법으로 병렬 스트림을 얻더라도 이후 요소 처리 과정은 병렬 처리 된다.
병렬 처리 성능
- 요소의 수와 요소의 처리 시간
- 스트림 소스의 종류
- 코어(Core)의 수
'개발(합니다) > Java&Spring' 카테고리의 다른 글
| [java-기초-18] 네트워크 기초 (2) | 2021.03.11 |
|---|---|
| [java-기초-17] IO 기반 입출력 (0) | 2021.03.10 |
| [java-기초-15] 컬렉션 프레임워크 (0) | 2021.02.22 |
| [java-기초-14] 람다식 (0) | 2021.02.14 |
| [java-기초-13] 제네릭 (0) | 2021.02.13 |



